Federated Learning for Insurance: Drive Safe, Pay Less

What if your car could negotiate a lower insurance premium for you without tattling on every single trip you take? It sounds like a privacy paradox, but it’s a challenge perfectly suited for a more thoughtful approach to system design and Federated Learning.
The Promise: Smarter Insurance, Real Privacy
Usage-Based Insurance (UBI) is built on a simple premise: good drivers should pay less. Insurers want to reward safe driving, but the traditional method—a telematic “black box” that sends all your driving data to a central server—feels like surveillance. For most people, the trade-off isn’t worth it.
That’s where Federated Learning comes in.
Instead of uploading raw data, learning happens right inside the vehicle. A small model in your car learns how you drive, how you accelerate, brake, handle corners, and now with more modern vehicles, even how your vehicle behaves on inclines, declines, and varying terrain types.
Only encrypted, anonymized model updates are sent—not your GPS trails or speed logs.
Federated Learning Architecture: At a Glance
Key Components:
Edge Agent: A small client embedded in the vehicle’s ECU.
Secure Aggregator: A cloud service that coordinates model updates.
Lightweight Protocols: Like MQTT or gRPC to enable efficient edge-cloud communication.
🔒 How Federated Learning Keeps Your Driving Data Private
Most drivers are rightfully concerned about sending sensitive data (like GPS trails, acceleration logs, or exact trip routes) to insurance companies. That’s why Federated Learning is designed to keep that data inside the car. And the data sent out out of the car is encrypted and anonymized.
Here’s what actually happens:
What Gets Sent (And What Doesn’t)
Instead of uploading raw trip data:
Your car trains a local model trained based on recent trips (e.g., how you brake, accelerate, or handle curves).
It creates a tiny model update, containing only mathematical adjustments.
This package is:
Encrypted so that even if intercepted, it’s useless.
Anonymized, meaning it contains no identity, no vehicle ID, only trip data.
Only the server that aggregates updates can understand how to use it, but not reverse it into real-world data.
In other words, even if a “man in the middle” intercepted your car’s update, they would not be able to access your location or trip data related to you.
Trip data is used to improve models but it’s not possible to relate a trip with a client.
This architecture mainly is focused in a decentralized approach, but all vehicles data will be analyzed by the main system too (using machine learning/AI) and the Global Model will be improved. Local Models can also be updated based on this learning. Here is how it works:
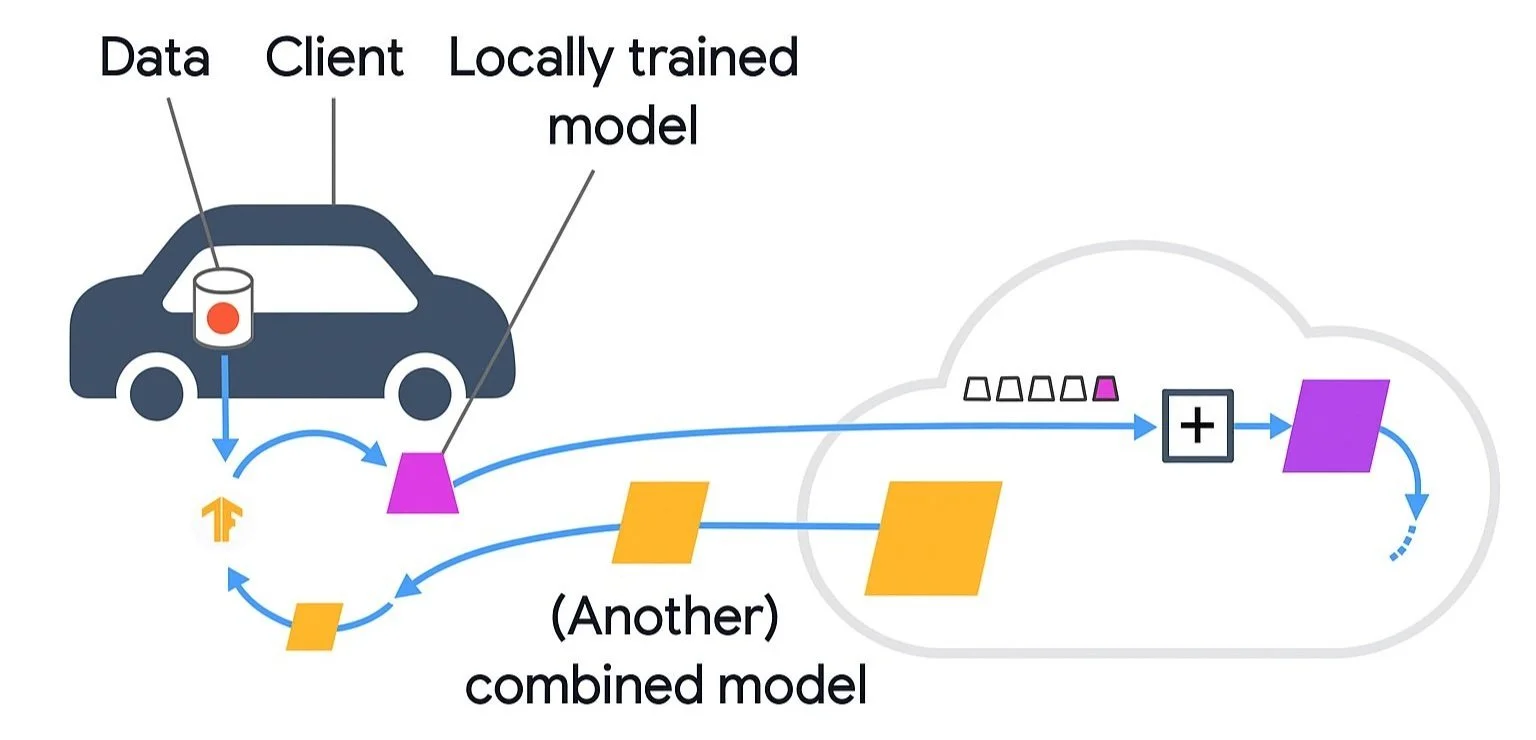
Secure Aggregation in Federated Learning
In Federated Learning, secure aggregation ensures that individual updates from vehicles (or clients) cannot be understood by anyone, not even the server collecting them.
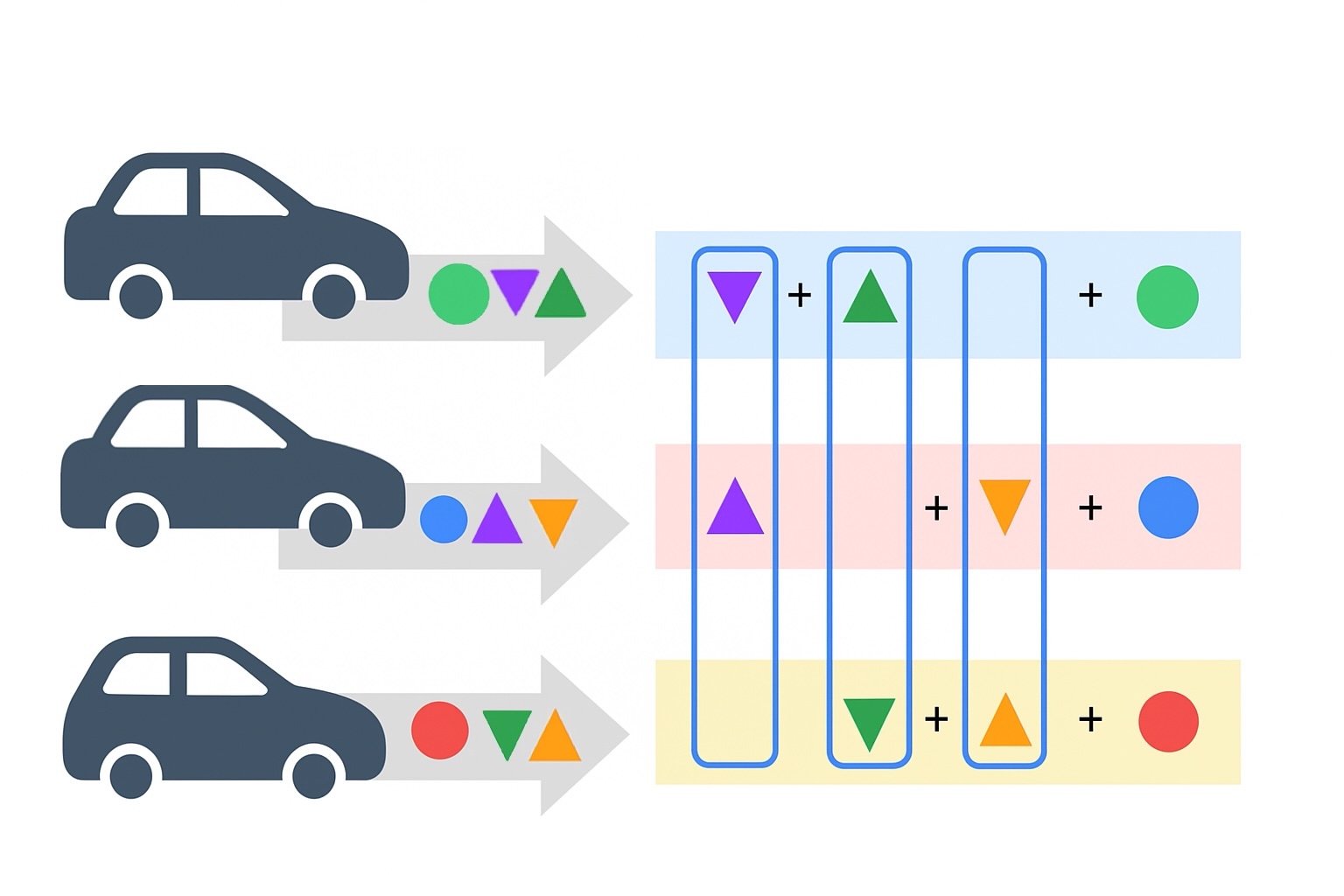
What’s happening in the image above:
Each vehicle (client) generates its own local model updates (represented by different shapes and colors).
Before sending updates to the server, each client obfuscates (hides) its true data by:
Mixing in extra values (random masks),
Ensuring that when all updates are combined, these masks cancel out.
The server receives only encrypted, obfuscated data from each client.
Once combined, the true aggregated relevant data can be extracted, but no individual contribution can be isolated.
Hence, the model can be updated without the ability to relate a driver/vehicle identity to a trip.
Why this matters:
No one can spy on a single vehicle’s data—even if they intercept the transmission.
The server learns only the sum of updates, not where they came from or what they individually contained.
This preserves privacy while still allowing the global model to improve based on real-world usage.
In short: the server gets the answers it needs, but not the details it shouldn’t know. That’s the beauty of secure aggregation in privacy-first AI systems. After this, Insurance companies can rank their customers by their driving style without knowing their actual location or trips.
⚠️ The Catch: Global Models Can Be Locally Unfair
Here’s where the problem begins: model drift.
Imagine two drivers:
Driver A in sunny mountainous Lisbon constantly goes uphill/downhill.
Driver B in rainy flat Amsterdam cruises on regular terrain.
Despite both driving safely, a global model might unfairly interpret Driver A’s behavior (frequent braking, engine revs, gear changes) as unsafe.
Below is a comparison of the two drivers based on sensor-inferred context and model interpretation:
🚙 Driver A (Lisbon Hills)
🚗 Driver B (Amsterdam Flats)
🔧 The Fix: Context-Aware Personalization
The solution isn’t to throw away the global model. It’s to evolve it.
These upgrades transform the system from a rigid judge to a context-aware partner.
Final thought
Federated Learning shows how we can build intelligent systems that respect privacy and adapt intelligently. But the real leap is in fairness, especially when sensor-rich environments give us the tools to personalize safely and ethically.
As architects and engineers, we must build systems that understand their context, not just the code or the data. The future isn’t just about machine learning… it’s about machine understanding.
Insurance companies can now fairly rank their customers while preserving privacy, promoting safe driving for everyone, and rewarding or penalizing drivers based on their behavior on the roads we all share.