BackPressure: Old-School Strategy for Modern Data

An F1 car screams down the main straight. But this isn’t just a machine built for speed; it’s a mobile data center. With AI now optimizing every decision in real time, from tire management to energy recovery, the car generates over a million data points per second through more than 300 sensors. All of it streams back to the pit wall, where engineers and machine learning models work together to extract insights and steer strategy.
But what happens if the pit-side AI, the system digesting all this information, can’t keep up? Do predictions get stale? Do decisions break? Does the whole race strategy collapse? Not if the system is built with proper flow control. This is where BackPressure comes in — a concept rooted in traditional systems, yet more important than ever.
In today’s AI-driven world, massive volumes of real-time data power everything from autonomous decisions to personalized user experiences. Overload is a constant threat. A service might run smoothly under normal conditions, but one spike in demand can knock it off balance. Resources get saturated, queues overflow, and crashes ripple across the system.
To thrive in this high-speed environment, systems must be more than fast. They need to be stable and resilient under pressure. One of the most reliable and time-proven ways to achieve this is through BackPressure, an old-school technique that remains essential in modern architectures.
1. The Core Problem: Data Overload
In almost any architecture, you have services that act as producers of data and others that act as consumers. The problem occurs when a producer sends messages faster than the consumer can process them. This creates a bottleneck; the consumer's internal queue or buffer fills up, its CPU usage spikes, and it can no longer keep up with the incoming demand.
This is a recipe for disaster, leading to memory exhaustion, data loss, and cascading failures.
2. The Solution: Applying BackPressure
BackPressure is a set of strategies that allow a consumer to send feedback to a producer, signaling it to slow down the rate of data emission. It's a flow control mechanism. Instead of letting the consumer drown, the system self-regulates to a sustainable pace, ensuring stability even during high load.
This creates a balanced and resilient system where components communicate their capacity.
An example of an interaction looks like this:
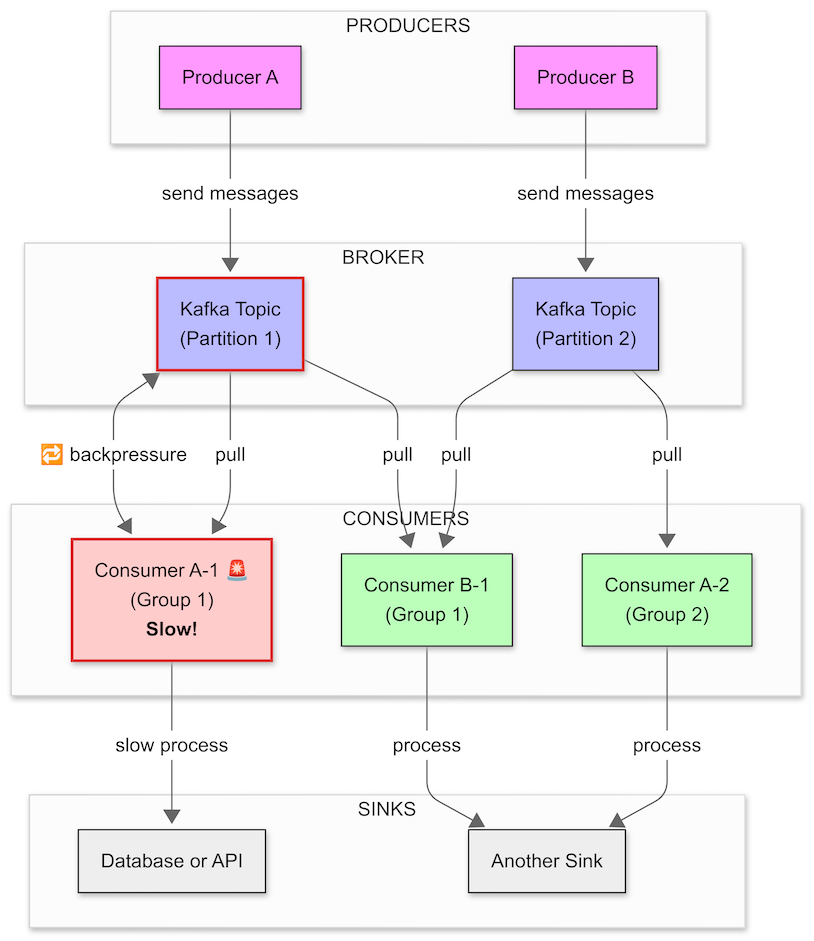
Overview
This diagram models a Kafka-based distributed system with:
Multiple producers
A Kafka broker with two partitions
Multiple consumers in different consumer groups
Different sinks
A BackPressure scenario on one slow consumer
Flow Explanation
🟪 Producers:
Producer A → sends messages to Partition 1
Producer B → sends messages to Partition 2
🟦 Kafka Broker:
Holds messages in Partition 1 and Partition 2
🟩 Consumers:
Consumer A-1 (Group 1) pulls from Partition 1 and is slow ⚠️
Consumer B-1 (Group 1) pulls from Partition 2
Consumer A-2 (Group 2) independently pulls from Partition 2
⬛ Sinks:
Consumer A-1 → processes slowly into Database or API
Consumer A-2 and Consumer B-1 → process into Another Sink
🔁 BackPressure Path:
Consumer A-1 is slow, which causes:
BackPressure on Partition 1 (shown with 🔁)
Kafka throttles delivery to Consumer A-1
If the partition fills up, Kafka may also throttle Producer A
🎯 Key Concepts Modeled:
Consumer Groups: Group 1 splits partitions across consumers; Group 2 reads all.
Independent BackPressure: Only affects the slow consumer and its partition.
Multiple Sinks: Show different downstream processing targets.
Visual Cues:
Red stroke and light red fill for the slow consumer and its partition
BackPressure icon clearly shows bidirectional feedback
3. Common BackPressure Strategies
subscription.request(10). The producer will send at most 10 items and then wait for the next request.
4. The F1 Analogy: A Lesson from the Pit Wall

To make this concept tangible, let's look at a Formula 1 team on race day.
The Producer: An F1 car with over 300 sensors, generating millions of data points per second about everything from tire pressure to the Energy Recovery System (ERS).
The Consumer: The race engineer on the pit wall, who must analyze this data in real-time to make critical strategy decisions.
If all 300 sensors streamed their data constantly and without regulation, the engineer would be hopelessly overwhelmed. It's impossible for a human to process that much information. The solution isn't for the engineer to "think faster"; it's to control the flow of information. This is where the analogy for BackPressure strategies comes into play:
Rate Limiting: The engineer’s dashboard only shows key metrics, updated at a regular interval (e.g., once a second), not thousands of times per second. The system throttles the data to a useful rate.
Request-Driven Flow: The engineer can explicitly request specific data when needed. "Show me the ERS charge levels for the last 10 seconds." This is a pull-based model where the consumer (the engineer) dictates what data it receives and when, which is the essence of reactive BackPressure.
Will it be AI-driven observability that predicts a failure before it happens? Or maybe intelligent agents that automatically apply back pressure across services?